Looking at the IT infrastructure at several production sites within my customer’s organization, we quickly noticed IT infrastructure components (mainly compute and storage related) that were not up to par from an availability and performance perspective. The production sites all run local business critical ERP application workloads that are vital to the business processes. After researching and discussing a lot, I proposed my customer a new blueprint. The blueprint consists of a new compute and storage baseline for the site local datacenters. The idea was to create a platform that allows for a higher availability and more performance while reducing costs.
We researched the possibility to step away from the traditional storage arrays and move towards a Hyper Converged Infrastructure (HCI) solution. Because IT is not the main business of the company, we were trying to keep things as simple as possible. We defined several ‘flavors’ to suit each production location to its needs. For example, the small sites will be equipped with a ROBO setup, the medium sites with a single datacenter cluster and the large factories are presented a stretched cluster solution. A stretched cluster setup will allow them to adhere to the stated availability SLA in the event of a large scale outages on the plant for their most important applications that do not offer in-application clustering/resiliency.
Benefits
Since my customer is running VMware solutions in all of its datacenters, VMware vSAN was the perfect fit. It allows the customer to lean on the already in-house VMware knowledge while being able to move towards less FTE for managing the storage backend. Implementing stretched clusters on multiple sites using storage arrays can be a daunting task. And although there are prerequisites, implementing VMware vSAN is implemented fairly easy, even if you opt for a stretched cluster configuration. This allowed for very short time from the moment of receiving hardware to a fully operational vSphere and vSAN cluster. Because the customer is in the process of renewing its IT infra for a number of sites, it really helps to tell the business we can deliver within weeks rather than months.
Using the VMware vSAN ready nodes allowed us to exceed the required storage capacity and performance requirements while being more cost efficient in comparison to traditional storage arrays. As management loves lowered costs, both capex and opex, HCI was the way to go. From a manageability point-of-view, it is a big plus that all VMware datacenters and (vSAN) clusters are managed from a centralized VMware vCenter UI. Another plus was the savings in rack units as those are scarce in some site-local datacenters.

During the project, we explored both the hybrid vSAN (spindles for capacity tier / flash devices for cache tier) and all-flash vSAN configurations. Now this was an interesting point, as an all-flash vSAN configuration allows you to use inline deduplication, compression and erasure coding (RAID 5/6) given you have the correct license. Both features contribute a lot in terms of storage capacity efficiency. In the end, we went for a hybrid setup because of budget constraints. Then again, the performance of the hybrid cluster was way better than the existing spindle based storage array it would replace.
Configuration
When you have designed your network infrastructure correctly, the configuration of the vSAN nodes can be as easy as clicking a button. The wizard really does the job for you. Just define your fault domains and you are ready to go.

We did ran into some small issues while deploying the external witness host. We used the nested ESXi option but experienced some OVF deployment troubles. Easy to fix but it did cost some time.
Once set up, we executed various performance tests to create a performance benchmark. We stress tested with Hammer DB and HCI bench. Benchmarking a new IT infra is difficult. It’s easy to extract some numbers, but how will the infra behave when real-life workloads are running on it? That is why we decided to run some Development, Testing, Acceptance (DTA) workloads on it. That quickly gave excellent insights and the customer was pretty excited to notice the increase of performance.
vSAN failure scenario validation
Testing and validating is probably the most important phase within a infrastructure renewal project. Having said that, I still come across environments that are not fully tested as a result of project time pressure. It is an absolute must to verify if an IT infra is behaving as expected during various failure scenarios. We did incorporate sufficient time within this project to verify the platform’s resiliency. You always need to be fully comfortable with every failure scenario. In the process of testing, document how the workloads are behaving in the event of outages.
We tested our new stretched vSAN environment to the fullest. From testing network outages including split brain scenarios up to simulating various and multiple disks and/or hosts failures. The following screenshots were taken during excessive testing. It all went ‘green’ once we were done.
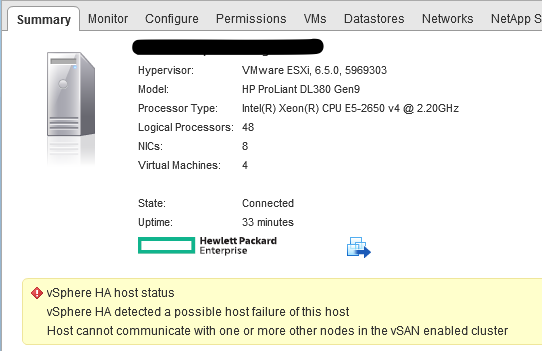
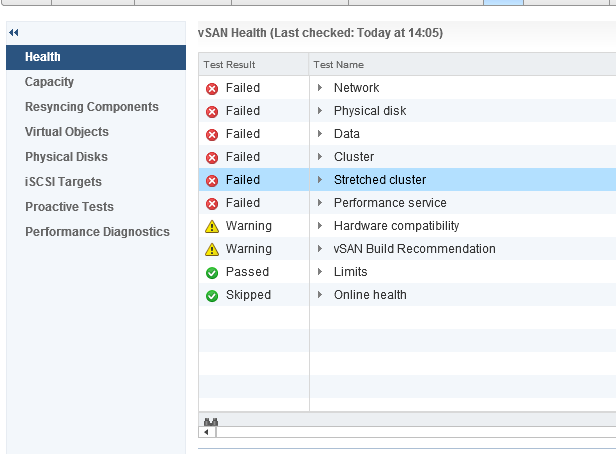
What we noticed was expected behaviour and we didn’t manage to break the vSAN environment while testing realistic failure scenarios. The result allowed us to get the approval to go forward with the migration plan for the production workloads.
To conclude
The most satisfying aspect about this project is that the customer was contented. They took the leap of faith to step away from traditional products to explore innovative solutions. Their trust was repaid with solid new infrastructures including all the benefits as mentioned in this post. Job well done. Always be innovating!
Disclaimer: Although this post almost sounds like a sales-pitch, the customer was genuinely happy with the results. And so was I.
Be careful. vSAN is great on paper but the software has had some pretty nasty bugs. And even with ready nodes, keep track of the firmware releases that address any potential storage problems. IMO it’s not as stable as other storage solutions.