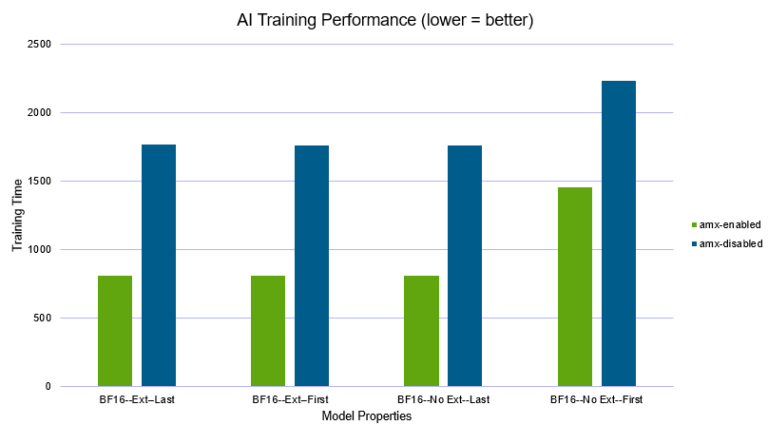




NKP with NC2: A Strong Architectural Choice
Nutanix Kubernetes Platform (NKP) has gained considerable momentum with existing and new customers, and rightly so. It makes managing Kubernetes clusters a breeze. Nutanix can manage K8s on various endpoints…