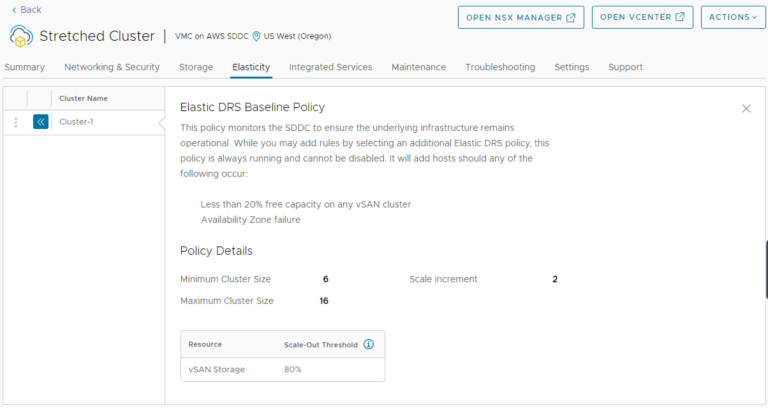
Elasticity is one of the many benefits of using VMware Cloud on AWS. Customers can configure a specific Elastic DRS (EDRS) policy for scaling out and scaling in their clusters running…
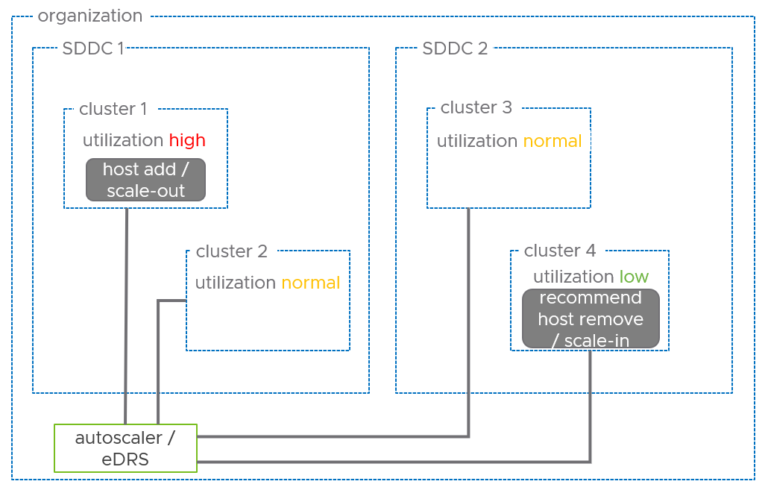
The Elastic Distributed Resource Scheduler (EDRS) is a unique policy-based approach for cloud elasticty with VMware Cloud on AWS. It lets customers scale their VMware Cloud on AWS clusters according…
With the launch of the i4i instance type for VMware Cloud on AWS, customers have asked how to benefit from the increased compute resources with the i4i instance. Recent performance studies…
vSphere 8 was announced at VMware Explore 2022 in San Francisco. Part of this new major release are vMotion updates. vMotion is extensively developed to support new workloads and is…
Advanced Cross vCenter vMotion (XVM), baked into vSphere, is one of my favorite capabilities. It allows for lightweight live bulk migrations between vCenter instances that are in different Single Sign-On…
Kernel modules play a crucial role in 3rd-party solutions tightly integrated with ESXi, such as the NVIDIA vGPU solution. Installing these solutions requires deploying the kernel module, or vib, on…