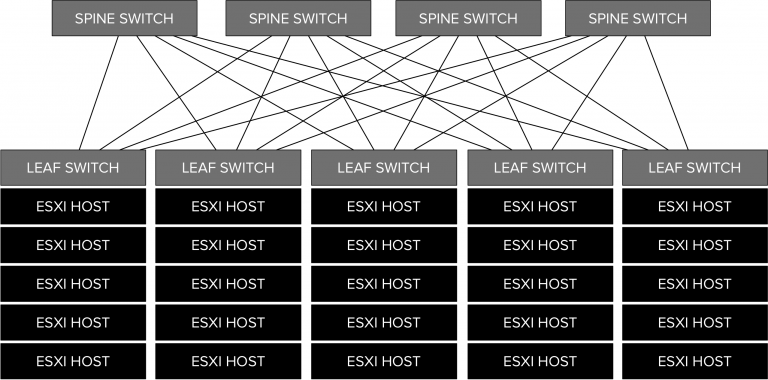
This is a short write-up about why you should consider a certain network topology when adopting scale-out storage technologies in a multi-rack environment. Without going into too much detail, I…
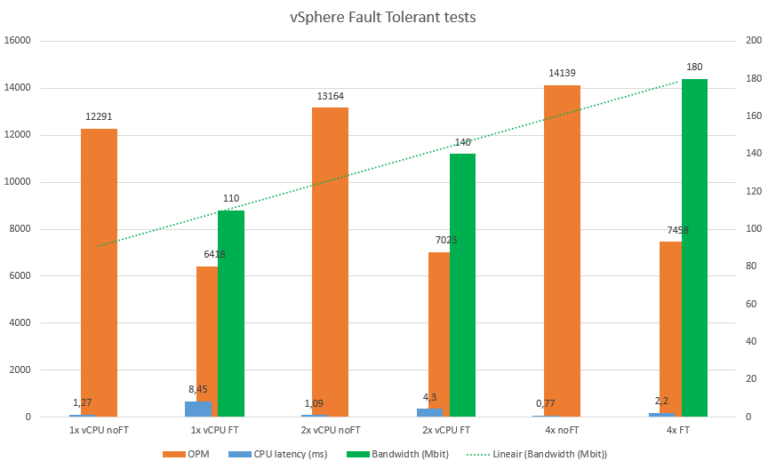
Triggered by some feedback on the VMware reddit channel, I was wondering what is holding us back in adopting the vSphere Fault Tolerance (FT) feature. Comments on Reddit stated that…
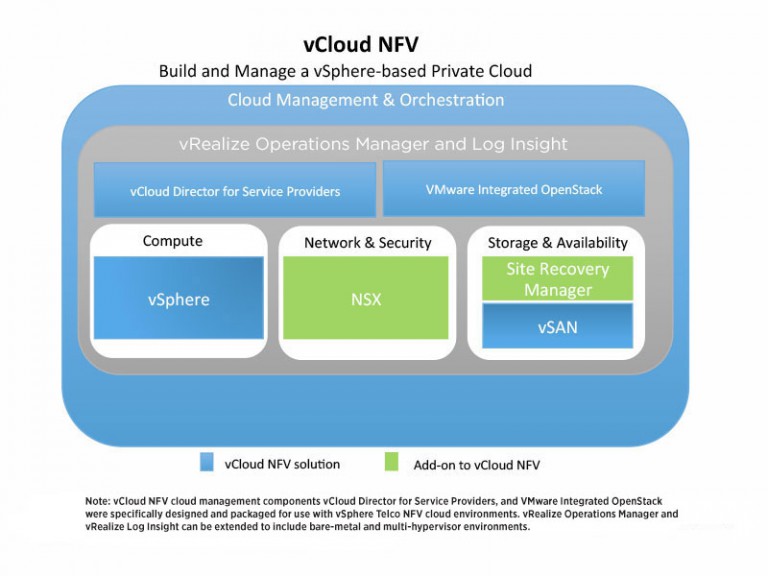
In my current role, I am involved in a lot of discussions around network functions virtualization, a.k.a. NFV. Talking about NFV in this post, I mean telco applications. By that I mean…