The good old TB vs TiB discussion is still around anno 2025. It remains confusing, and if misinterpreted, can have an impact when it comes to sizing storage and/or memory…
VMworld 2019 will mark my first edition as a VMware employee. Thus, I will be working more and have less time to attend sessions myself. However, there are always things…
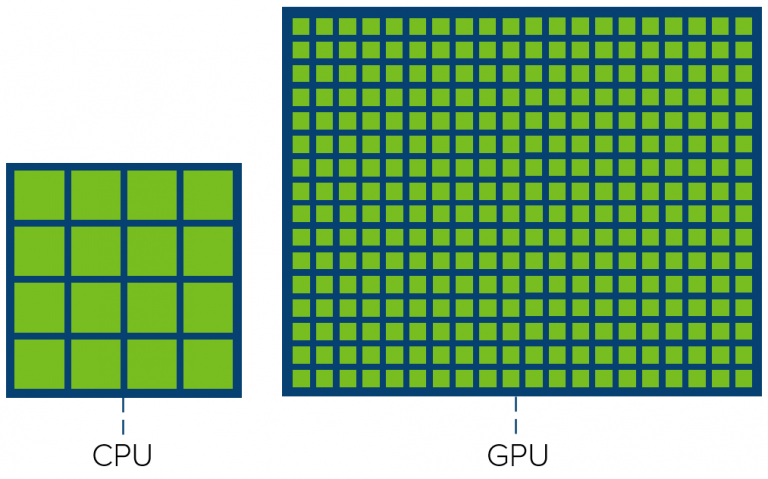
A Graphics Processor Unit (GPU) is mostly known for the hardware device used when running applications that weigh heavy on graphics, i.e. 3D modeling software or VDI infrastructures. In the…
I am incredibly excited to announce that I will be joining VMware! Even more thrilled that I will be a member of the Cloud Platform Business Unit, in the R&D…
In June of this year, Frank and I published the vSphere 6.5 Host Resources Deep Dive, and the community was buzzing. Twitter exploded, and many community members provided rave reviews. This excitement caught Rubriks attention,…