The vSphere vMotion feature enables customers to live-migrate workloads from source to destination ESXi hosts. Over time, we have developed vMotion to support new technologies. The vSphere 7 release is no exception to that, as we greatly improved the vMotion feature. The vMotion enhancements in vSphere 7 include a reduced performance impact during the live migration and a reduced stun time. This blog post will go into detail on how the vMotion improvements help customers to be comfortable using vMotion for large workloads.
To understand what we improved for vMotion in vSphere 7, it is imperative to understand the vMotion internals. Read the vMotion Process Under the Hood to learn more about the vMotion process itself.
Large VM vMotion Challenges
vSphere is the perfect platform to host large virtual machines (VMs), also referred to as “Monster” VMs, with the current per VM resource maximums set to 256 vCPU’s and 6 TB of memory. However, we noticed that customers running workloads in large VMs were not always comfortable live-migrating these VMs. That was due to a potential impact on workload performance during the vMotion process, and a switch-over (stun) time that took too long.
For example, large transactional database platforms that are dealing with a substantial number of I/Os could experience performance degradation during a vMotion, although the precise impact strongly depends on the workload’s characteristics & sizing. The enhanced logic for vMotion in vSphere 7 overcomes all these challenges and allows us to live-migrate large workloads without significant impact on performance or availability.
Memory Pre-copy Optimizations
As explained in this video, we need to keep track of all the changed memory pages for a VM during its vMotion operation. Because it is a live-migration, the guest OS inside the VM will keep writing data to memory during the vMotion. We need to track and resend memory pages that are overwritten during a vMotion.

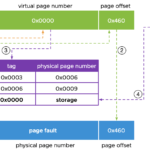
The vMotion process installs a page tracer on all the vCPUs that are configured for the VM. By doing so, vMotion understands what memory pages are being overwritten. This is referred to as a ‘page fire’ during page tracing. We are distributing the tracing work to all the vCPU’s for the VM that is live-migrated.
To install the page tracer and to process a page fire, the vCPUs are briefly stopped. It’s only microseconds, but stopping all vCPUs disrupts the workload. Scaling up the compute resources of a VM increases the impact of a vMotion operation. After stopping the vCPUs for the tracing work, all memory Page Table Entries (PTE) are set to read-only, and the Translation Lookaside Buffers (TLB) are flushed to avoid TLB hits and force a page table walk so the vMotion process fully understands what memory pages have been overwritten. Learn more on these memory constructs in this blog post. The method described here is referred to as a “Stop-based Page Trace Install.”
How is it done in vSphere 7?
The biggest impact comes from having to stop all the vCPUs for page tracing. What if we can install the page tracers without the need to stop all vCPUs? With vSphere 7, we are introducing the “Loose Page Trace Install.” The method for page tracing mostly remains the same but instead of using all vCPUs, we now only claim one vCPU to perform all the tracing work. All the other vCPUs that are entitled to the VM just continue to run the workload without interruption.

The page tracer will be installed on the one claimed vCPU and sets all the PTEs to read-only. The TLB is vCPU specific, so each vCPU still needs to flush its TLB. But this happens at different times to minimize the impact. Overall, this method is far more efficient as only one vCPU is used for page tracing.
Page Table Granularity
So we reduced the cost of tracing, but what if we can make it even more efficient? We optimized the way we set memory to read-only, meaning there’s less work to be done on this part. Less work means increased efficiency. The way memory is set to read-only prior to vSphere 7 is on a 4KB page granularity. All the individual 4KB pages needed to be set to read-only access.
As of vSphere 7, the Virtual Machine Monitor (VMM) process will set the read-only flag at a much larger granularity, on 1GB pages. If a page fire (a memory page is overwritten) occurs, the 1GB PTE is broken down into 2MB and 4KB pages. VMware engineers have seen that a VM is typically not touching all of its memory during a vMotion process. The memory working set size during a vMotion is typically only 10-30%. If more memory is used during the vMotion time, the cost efficiency will be less.
Switch-over Phase Enhancements
All the enhancements we have discussed so far are done in the memory pre-copy phase, where the tracing happens. Once we reach memory convergence, meaning almost all memory is copied to the destination host, vMotion is ready to switch-over to the destination ESXi host. In this last phase, the VM on the source ESXi host is suspended and the checkpoint data is sent to the destination host. Remember that we want the switch-over time (stun time) to be 1 second or less. For large VMs, this has become a challenge because of workload sizes that have increased over time.
In the switch-over phase, we send over the checkpoint data and the memory bitmap. The memory bitmap is used to track all the memory of a VM. It know what pages are overwritten and still need to be transmitted the destination ESXi host. As vMotion transfers the last memory pages, the VM on the destination host begins to power on. But it might still need the last pages left for transmission. To identity these pages on the destination, we use the bitmap that is transferred from the source. If customers overcommit memory, the swapped-out pages are tracked in the optional swap bitmap.

The memory bitmap is sparse. It contains the last memory pages and information of all the memory pages in use by the VM. The memory bitmap for a VM with 1GB of memory is 32KB in size. It will only take milliseconds to transfer 32KB: no problem!
How vSphere 7 does it
With VMs running 6TB of memory (or potentially even more in the future), the bitmap is already 192MB. To stay under 1 sec of switch-over time, we need the bitmap to be smaller as sending over 192MB could take up to a second or more. What if we could compact the bitmap, and only send over the information that you really need?

At this stage we have already copied most of the memory pages, so only the last remaining memory pages need to be sent. Using a compacted memory bitmap, vMotion is able to send bitmaps for large VMs over in milliseconds, drastically lowering the stun time.
Performance Improvements
These enhancements to vMotion in vSphere 7 allow workloads to be live-migrated with almost no performance degradation during a vMotion. The following diagram is an example of a test to show you the potential performance gains in vSphere 7. The testbed is a large VM (72 vCPU / 512GB) running a HammerDB workload. We monitor the commits/sec over a timeline with a 1 second granularity.
A couple of key takeaways that we noticed during this test in vSphere 7, compared to vSphere 6.7, are:
- We no longer experience the performance impact during the page trace phase.
- The stun time remains within 1 second instead of taking multiple seconds.
- The overall live-migration time is almost 20 seconds shorter.
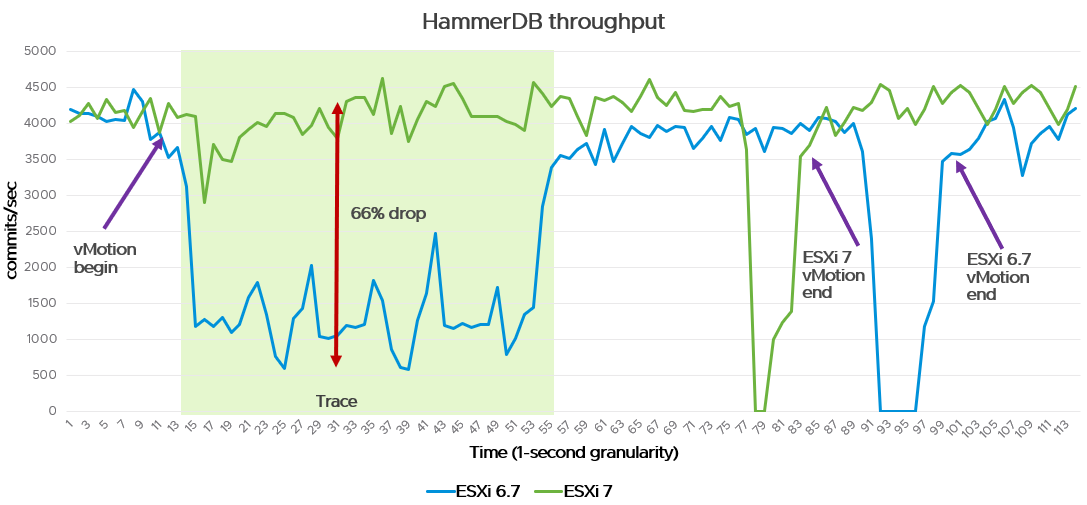
Your mileage may vary depending on vMotion network configurations and VM sizing, but this is an exemplary test to show the potential benefits of these vMotion improvements.
To Conclude
The improvements made in vMotion with vSphere 7 are enormous and greatly reduce the cost paid for a vMotion. You don’t need to anything to enjoy the new and improved vMotion logic, other than to upgrade your systems to vSphere 7 and up.
More Resources
–originally authored and posted by me at https://blogs.vmware.com/vsphere/2020/03/how-is-virtual-memory-translated-to-physical-memory.html–