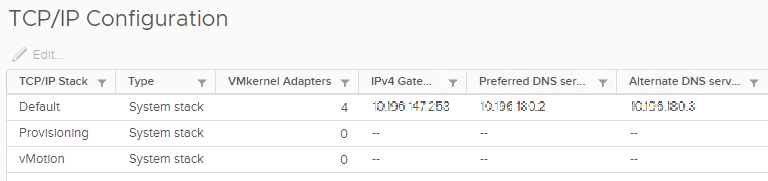
A common question arises when customers are migrating workloads between ESXi hosts, clusters, vCenter Servers, or data centers. What network is being used when a hot or cold migration is…
In my latest blog posts, we discussed the vSphere vMotion process in detail. Those blog posts are now accompanied by light board videos (including subtitles/closed captions!). Be sure to check…
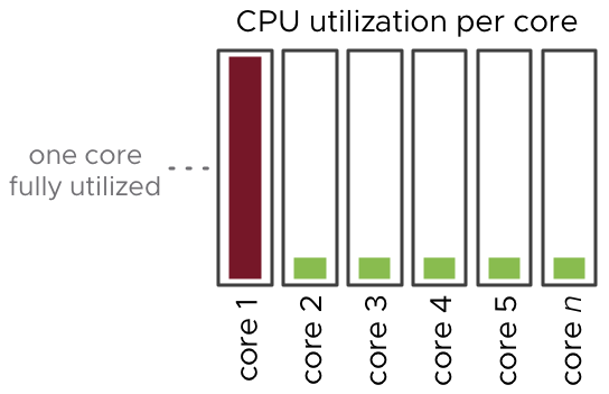
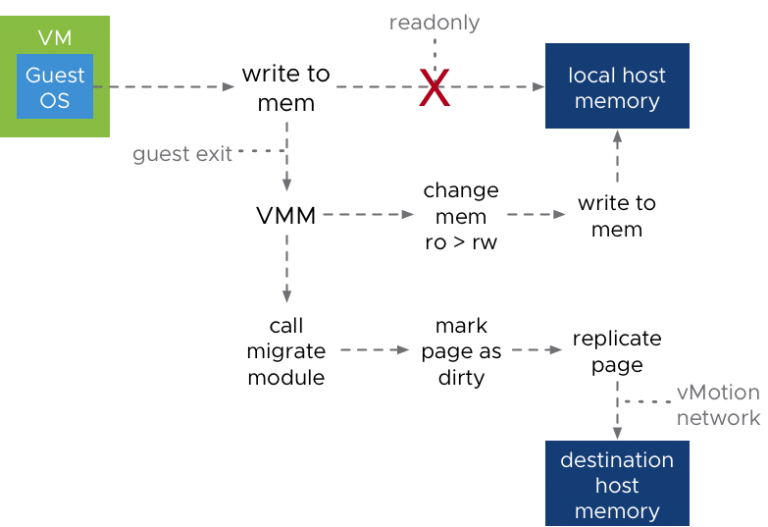
In an earlier blog post, The vMotion Process Under the Hood, we went over the vMotion process internals. Now that we understand how vMotion works, let's go over some of…
VMworld 2019 will mark my first edition as a VMware employee. Thus, I will be working more and have less time to attend sessions myself. However, there are always things…
The VMware vSphere vMotion feature is one of the most important capabilities in today's virtual infrastructures. Since its inception in 2002 and its release in 2003, it has allowed us…
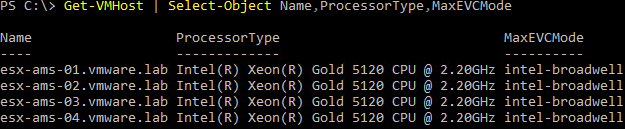
vSphere Enhanced vMotion Compatibility (EVC) ensures that workloads can be live migrated, using vMotion, between ESXi hosts in a cluster that is running different CPU generations. The general recommendation is…