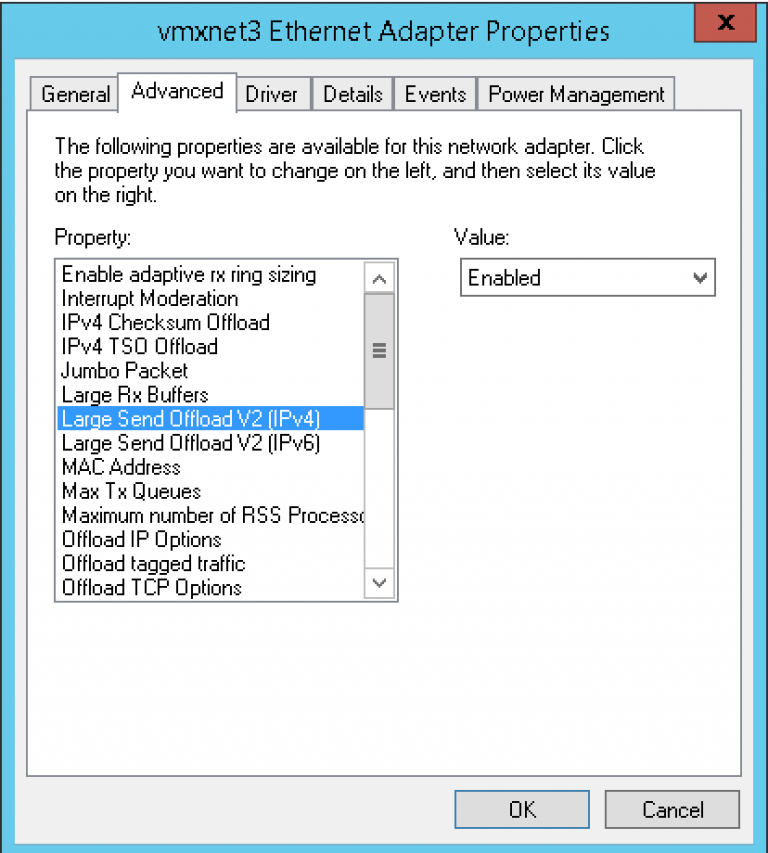
TCP Segmentation Offload (TSO) is the equivalent to TCP/IP Offload Engine (TOE) but more modeled to virtual environments, where TOE is the actual NIC vendor hardware enhancement. It is also…
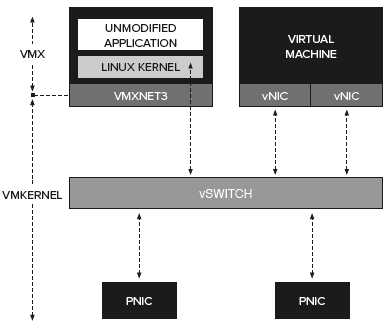
The VMkernel is relying on the physical device, the pNIC in this case, to generate interrupts to process network I/O. This traditional style of I/O processing incurs additional delays on…