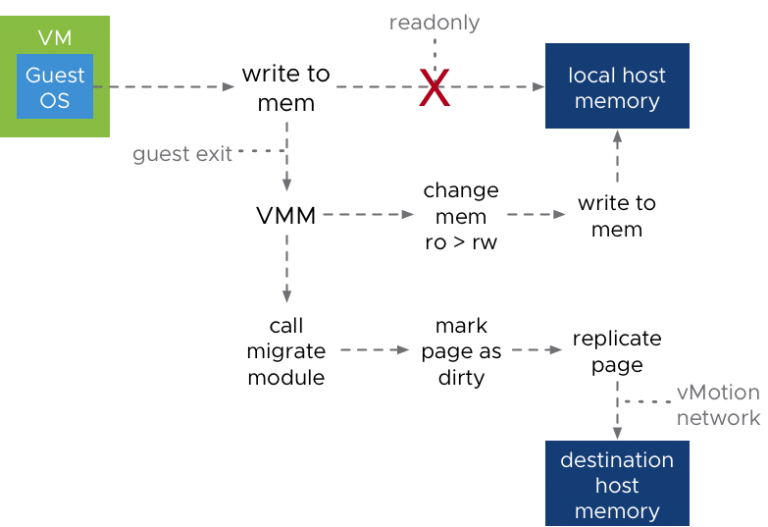
The VMware vSphere vMotion feature is one of the most important capabilities in today's virtual infrastructures. Since its inception in 2002 and its release in 2003, it has allowed us…
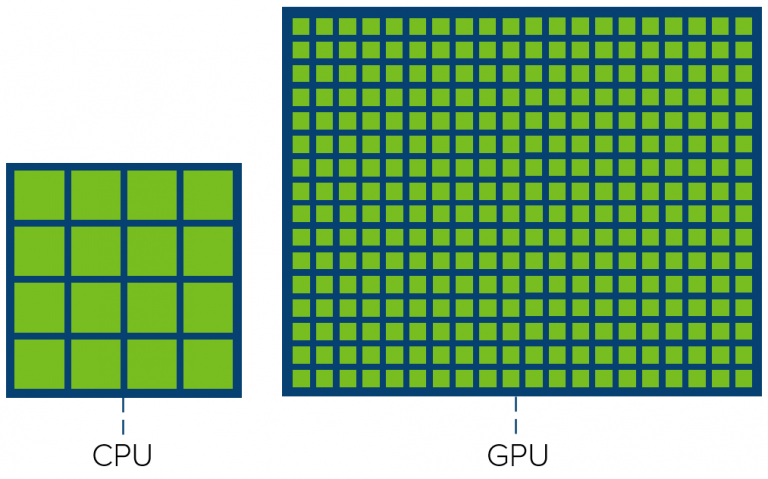
A Graphics Processor Unit (GPU) is mostly known for the hardware device used when running applications that weigh heavy on graphics, i.e. 3D modeling software or VDI infrastructures. In the…
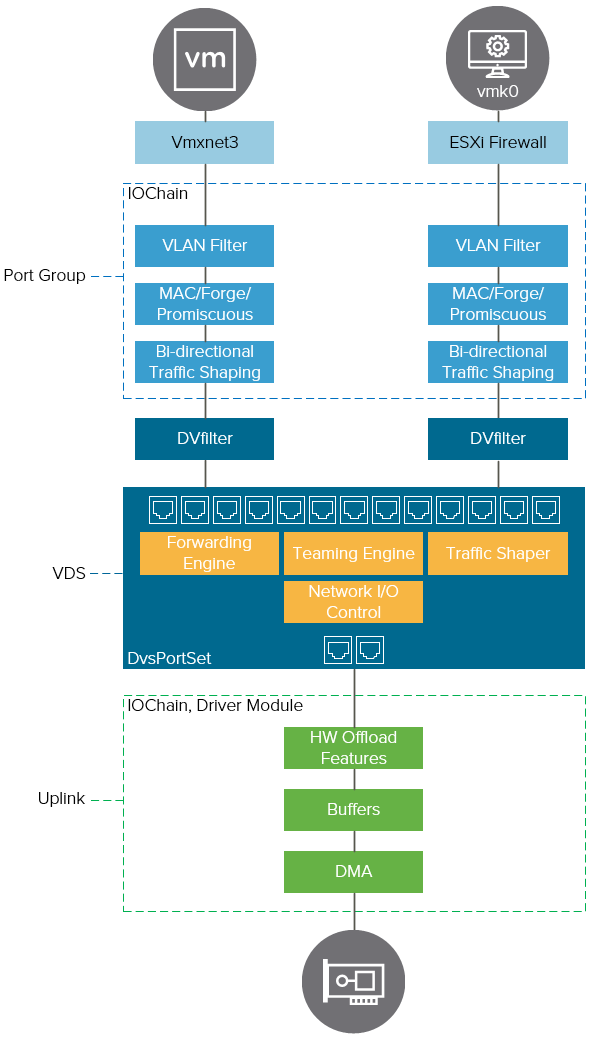
In the previous post about the ESXi network IOchain we explored the various constructs that belong to the network path. This blog post builds on top of that and focuses…
In this blog post, we go into the trenches of the (Distributed) vSwitch with a focus on vSphere ESXi network IOChain. It is important to understand the core constructs of the…
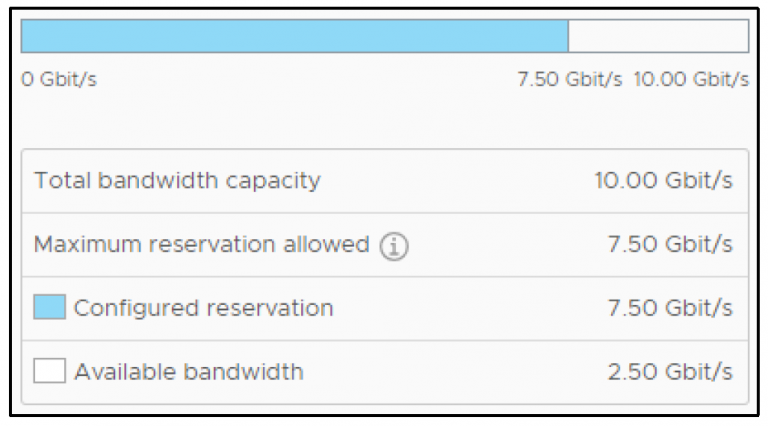
To enforce bandwidth availability, it is possible to reserve a portion of the available uplink bandwidth using vSphere Network I/O Control (NIOC). It may be necessary to configure bandwidth reservations…
vSphere network quality control features like the Network I/O Control (NIOC) feature are focused on the virtual networking layer within a VMware vSphere environment. But what about the physical network…