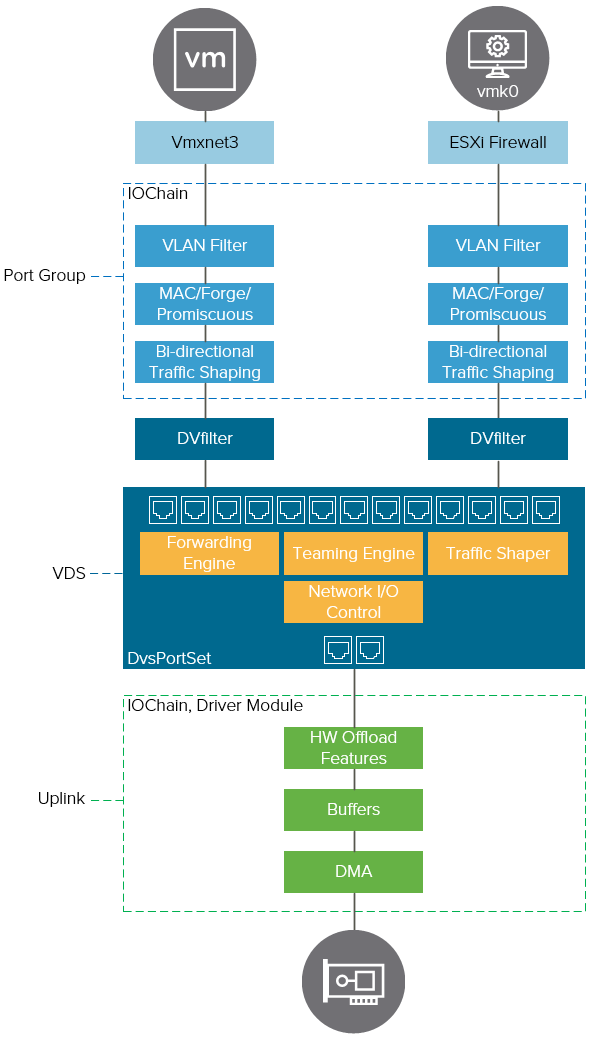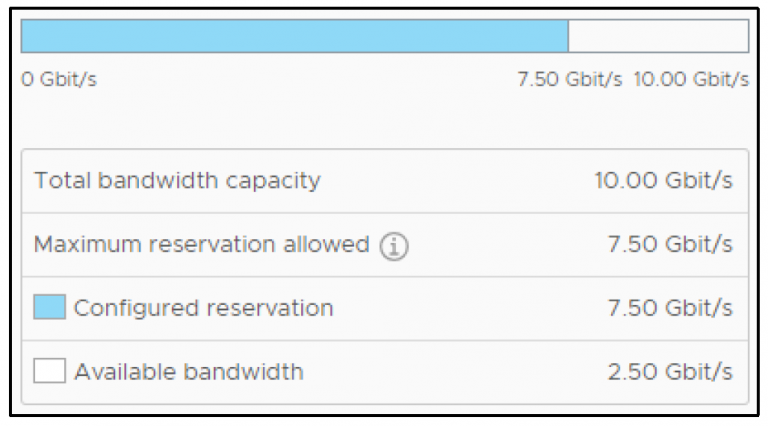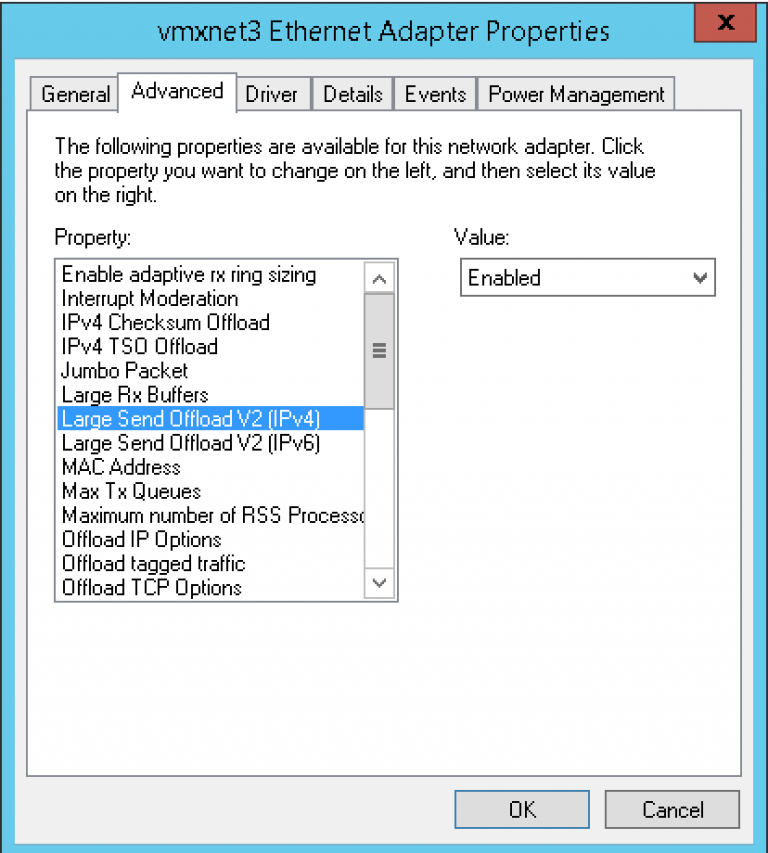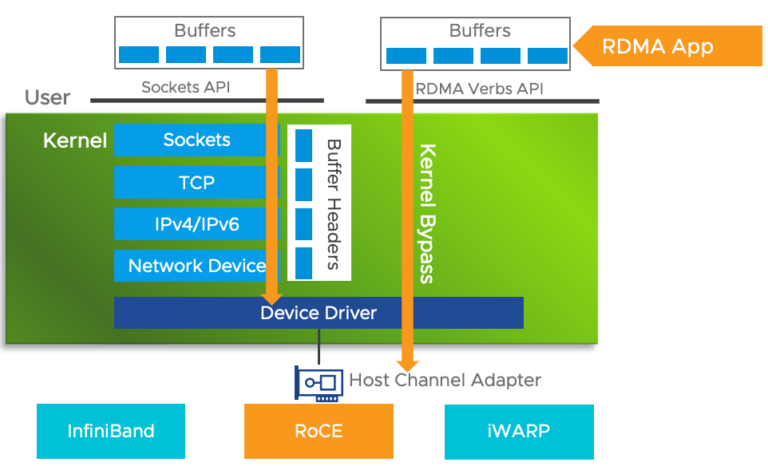
The Basics of Remote Direct Memory Access (RDMA) in vSphere
Remote Direct Memory Access (RDMA) is an extension of the Direct Memory Access (DMA) technology, which is the ability to access host memory directly without CPU intervention. RDMA allows for…