During AWS re:Invent 2023, the new instance type for VMware Cloud on AWS was announced; The disaggregated M7i.metal-24xl instance type! This means customers benefit from the latest compute innovations and freedom of choice when it comes to storage options.
The new M7i.metal-24xl instances are a perfect fit for entry-level SDDCs (2-4 hosts). We see a lot of use cases that make sense for this new option, including your typical general-purpose workloads, but also database backends and AI/ML applications because of the embedded accelerators as part of the 4th generation Intel Xeon CPU. This blog post details technical information with benchmark news and quick demos showcasing the new instance type.
Update May ’24: VMware by Broadcom decommissioned the availability of the M7i instance for VMware Cloud on AWS.
Compute Specs
The M7i.metal-24xl instance uses Intel Sapphire Rapids CPU packages. Sapphire Rapids is a codename for Intel’s fourth-generation Xeon Scalable CPUs. It comes with 48 physical cores, with Hyper-Threading enabled resulting in 96 logical processors. The cores have a base frequency of 3.2 GHz with an all-core Turbo frequency up to 3.8 GHz. Memory capacity is 384GB per host.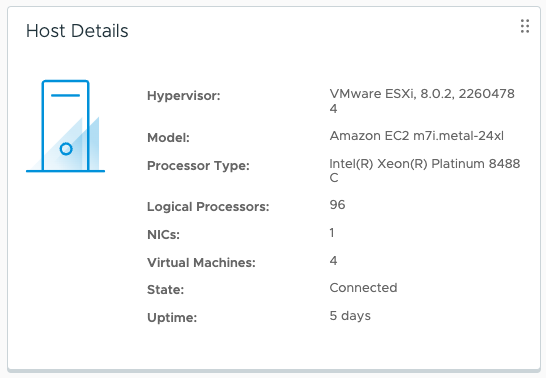
Accelerate AI/ML
One of the benefits of running workloads on the 4th generation Intel Xeon CPU package is its Intel Advance Matrix Extensions (AMX) accelerator, which accelerates matrix multiplication operations for deep learning (DL) inference and training workloads. With the 1.24 SDDC version release for VMware Cloud on AWS, the vSphere 8 Update 2 bits are used with VM hardware version 20. Be aware that by default a VM is created using VM hardware version 19 today, so you explicitly need to configure it with version 20 as shown in the demo.
VM hardware version 20 exposes the Intel AMX instructions to the guest OS as seen in the following screenshot. This helps to improve the performance of AI/ML workloads, analytics, and HPC workloads. A great example of this is found in this compelling blog post.
Together with Intel, we have tested a PyTorch-based training and inference for a general-purpose AI/ML use case. The latest version of PyTorch combined with Intel PyTorch Extension (IPEX) was used to test the performance of a general-purpose dataset for training and inference.
Brain Floating Point format, Bfloat16 or BF16 instructions are used in systolic arrays to accelerate matrix multiplication operations, like with image recognition or Large Language Models (LLM). Intel AMX enables BF16. It provides a 2X improvement over the traditional FP32 (Single-precision floating-point format) for training and about 15-20% improvement for Inference.
Using a single VM running both VM hardware version 19 (no Intel AMX) and version 20 (Intel AMX), we trained the app against the MIT Indoor scenes dataset. We measured the training time to see the benefit of using VM hardware version 20 with Intel AMX: 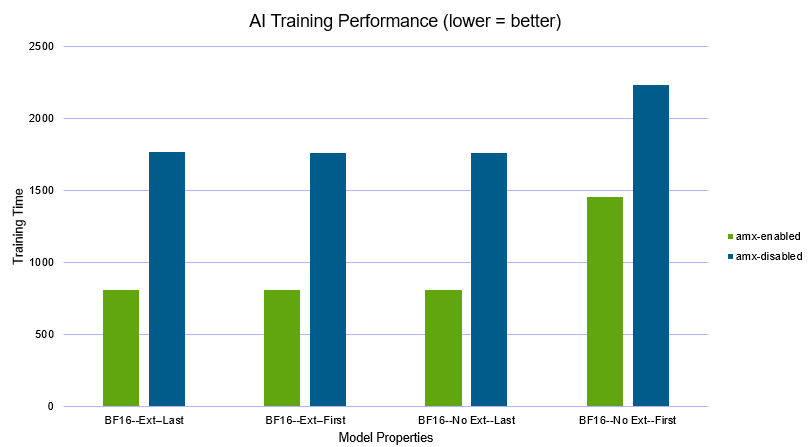
Intel AMX is providing approx. 50% of training time here. No additional devices required, just using the built-in accelerators that help improve performance efficiency. Once trained, the inference app also showed improvements using Intel AMX. Both the inference time and average images/sec are measured, showing up to 20% performance gain with Intel AMX.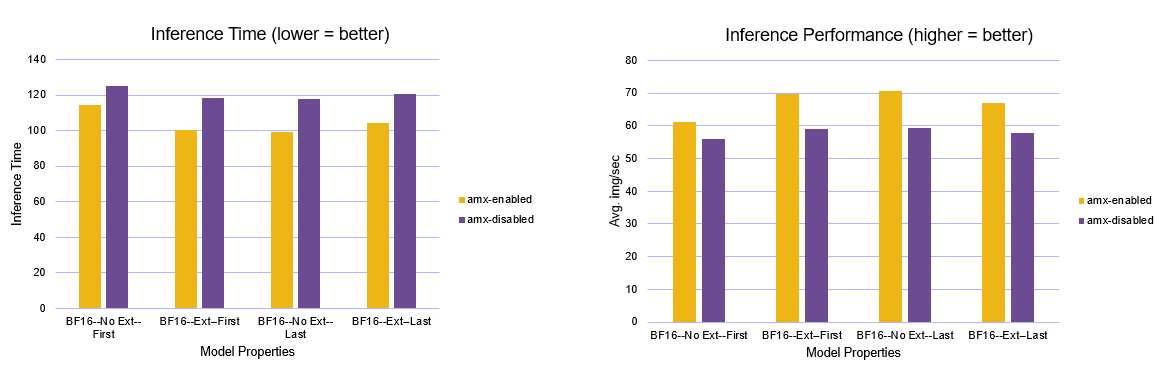
Depending on the type of ML dataset, one could argue the use of GPU is always better for parallel processing, which is typically important with inferencing workloads. But decent results can also be achieved using correct CPUs as mentioned in this blogpost.
–originally authored and posted by me at https://vmc.techzone.vmware.com/closer-look-m7i-instance-vmware-cloud-aws–

