I had some discussion about AWS (Amazon Web Services) and how to connect to their services, specifically when you run production workloads on virtual machines in AWS. Bringing workloads to…
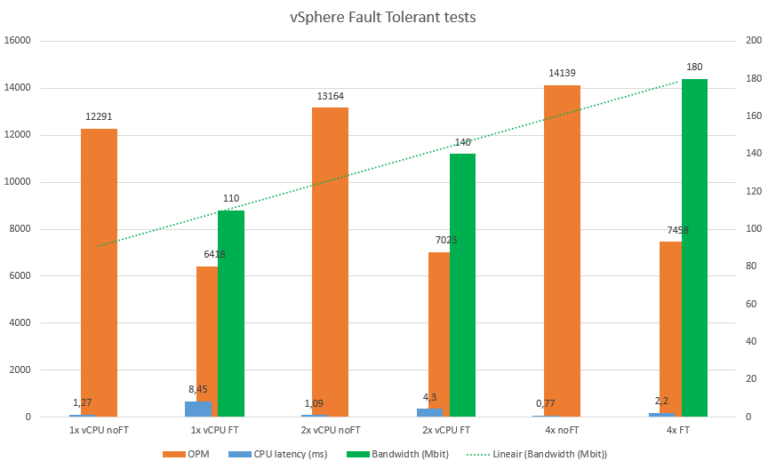
Triggered by some feedback on the VMware reddit channel, I was wondering what is holding us back in adopting the vSphere Fault Tolerance (FT) feature. Comments on Reddit stated that…
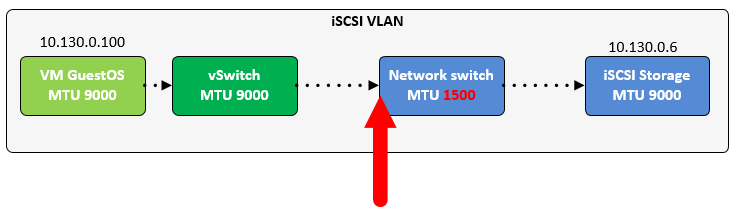
Even though the jumbo frame and the possible gain and risk trade-offs discussion is not new, we found ourselves discussing it yet again. Because we had different opinions, it seems like…
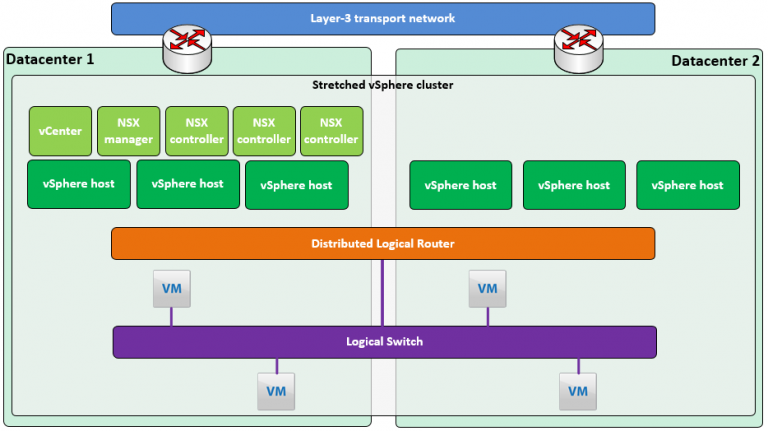
Last NLVMUG I was talking about stretched clusters. My presentation elaborated somewhat on how VMware NSX can help you deal with challenges that arise when deploying a stretched cluster solution.…
I've noticed some distress on the web because, with the release of Synology DSM version 6.0, it is no longer possible to use the vconfig command. This command was used to configure…